Transformer初探
Transformer
Chapter 1: Transformer的誕生
2018年10月,Google發表了一篇論文,推出了BERT模型,橫掃NLP 11項任務。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
1.2 Transformer的優勢
相比之前佔領市場的 [[LSTM]] 和 [[GRU]] 模型,Transformer具有兩個優勢:
- Transformer能夠利用分佈式GPU進行並行訓練,提升模型訓練效率。
- 在分析預測更長的文本時,Transformer在捕捉間隔較長的語義關聯效果更好。
Chapter 2: Transformer架構解析
2.1 認識Transformer架構
學習目標:
- 瞭解Transformer模型的作用
- 瞭解Transformer總體架構中各組成部分的名稱
Transformer模型的作用:
- 基於seq2seq架構的Transformer模型可以完成NLP領域的典型任務,如機器翻譯、文本生成等。同時也可以用於建構預訓練語言模型,以支持不同任務的遷移學習。
聲明:
- 在接下來的架構分析中,我們將假設使用Transformer模型架構處理從一種語言文本到另一種語言文本的翻譯工作,因此很多命名方式遵循NLP中的規則。例如:Embedding層將稱作文本嵌入層,Embedding層產生的張量稱為詞嵌入張量,最後一維將稱為詞向量等。
Transformer總體架構圖
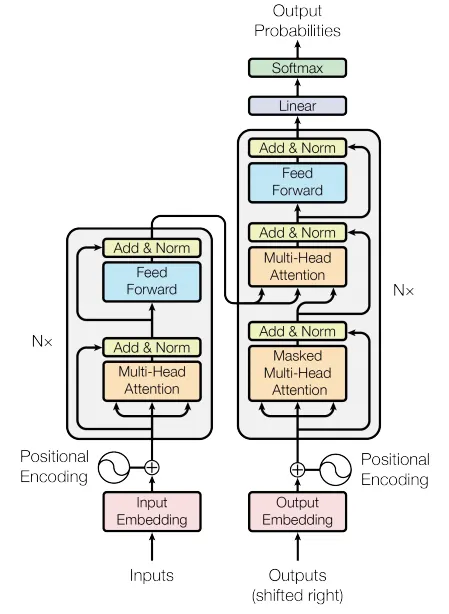
Transformer總體架構可分為四個部分:
- 輸入部分
- 輸出部分
- 編碼器部分
- 解碼器部分
輸入部分包含:
- Input Embeddings
- Position Encodings
輸出部分包含:
- Softmax
- Linear
編碼器部分包含:
- 由N個編碼器層堆疊而成
- 每個編碼器層由兩個子層組成:
- 第一個子層:Multi-head Attention 和 Add & Norm
- 第二個子層:MLPs 和 Add & Norm
解碼器部分包含:
- 由N個解碼器層堆疊而成
- 每個解碼器層包含三個子層:
- 第一層:Masked Multi-head Attention 和 Add & Norm
- 第二層:Multi-head Attention 和 Add & Norm
- 第三層:MLPs 和 Add & Norm
2.2 輸入部分實現
學習目標:
- 瞭解文本嵌入層和位置編碼的作用
- 掌握文本嵌入層和位置編碼的實現過程
輸入部分包含:
- Input Embeddings
- Position Encodings
文本嵌入層作用:
- 無論是源文本嵌入還是目標文本嵌入,都是為了將文本中的詞彙數字表示轉換為向量表示,希望在高維空間中捕捉詞彙間的關係。
文本嵌入層代碼分析:
1 | import torch |
位置編碼器的作用:
- 由於在Transformer的架構中,沒有直接對詞彙位置信息進行處理,因此需要在Embedding層後加入位置編碼器。位置編碼器能夠將詞彙位置訊息融入詞嵌入張量中,以彌補位置訊息的缺失。
位置編碼器的代碼分析:
1 | import torch |
- 小節總結:
- 學習了文本嵌入層的作用:將詞彙的數字表示轉為向量表示,以在高維空間中捕捉詞彙間的關係。
- 學習並實現了文本嵌入層的類:
Embeddings- 初始化函數包含
d_model(詞嵌入維度)和vocab(詞彙總數)參數,內部使用nn.Embedding進行詞嵌入。 forward函數中,將輸入x傳入到Embedding的實例化對象中,並乘以根號下d_model進行縮放。
- 初始化函數包含
- 學習了位置編碼器的作用:
- 因Transformer中沒有直接處理詞彙位置資訊的機制,需在Embedding層後加入位置編碼器來補充位置訊息。
- 學習並實現了位置編碼器的類:
PositionalEncoding- 初始化函數包含
d_model(詞嵌入維度)、dropout(置0比率)、max_len(句子最大長度)。 forward函數輸入參數x,輸出加入位置編碼訊息的詞彙嵌入張量。
- 初始化函數包含
- 實現了可視化分佈曲線:
- 確保同一詞彙隨位置不同,其位置嵌入向量會變化;
cos和sin的範圍控制了嵌入值大小,有助於梯度快速計算。
- 確保同一詞彙隨位置不同,其位置嵌入向量會變化;
2.3 編碼器部分實現
2.4 解碼器部分實現
2.5 輸出部分實現
2.6 模型建構
2.7 模型基本測試運行
2.8 參考文獻:
本部落格所有文章除特別聲明外,均採用CC BY-NC-SA 4.0 授權協議。轉載請註明來源 JayLan's Blog!